3. Machine Learning for Classification¶
- 3.1 Churn prediction project
- 3.2 Data preparation
- 3.3 Setting up the validation framework
- 3.4 EDA
- 3.5 Feature importance: Churn rate and risk ratio
- 3.6 Feature importance: Mutual information
- 3.7 Feature importance: Correlation
- 3.8 One-hot encoding
- 3.9 Logistic regression
- 3.10 Training logistic regression with Scikit-Learn
- 3.11 Model interpretation
- 3.12 Using the model
- 3.13 Summary
- 3.14 Explore more
- 3.15 Homework
We’ll use logistic regression to predict churn
3.1 Churn prediction project¶
- Dataset: https://www.kaggle.com/blastchar/telco-customer-churn
- https://raw.githubusercontent.com/alexeygrigorev/mlbookcamp-code/master/chapter-03-churn-prediction/WA_Fn-UseC_-Telco-Customer-Churn.csv
The project aims to identify customers that are likely to churn or stoping to use a service. Each customer has a score associated with the probability of churning. Considering this data, the company would send an email with discounts or other promotions to avoid churning.
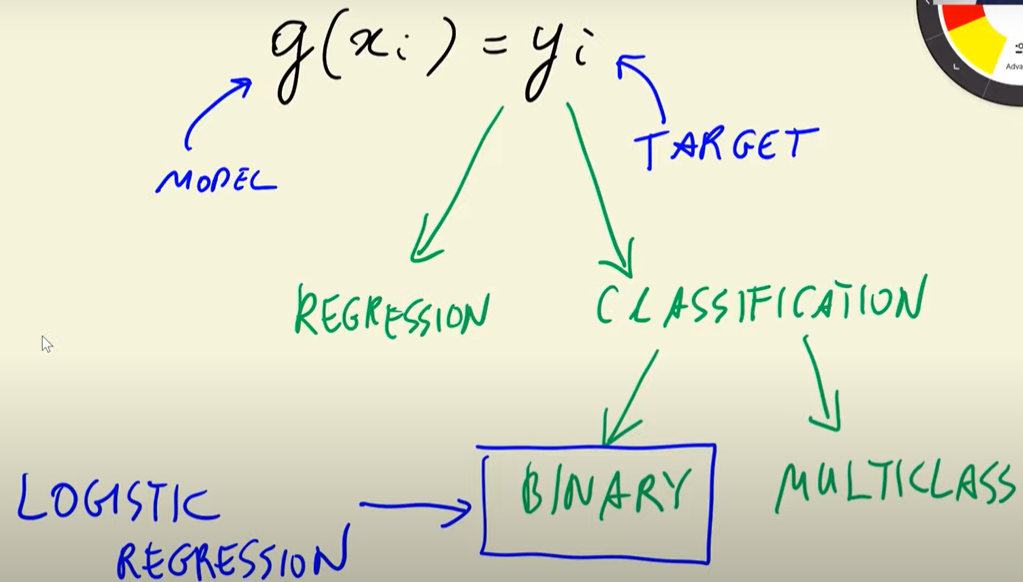
The ML strategy applied to approach this problem is binary classification, which for one instance can be expressed as:
g(xsubi) = ysubi
In the formula, yi is the model’s prediction and belongs to {0,1}, being 0 the negative value or no churning, and 1 the positive value or churning. The output corresponds to the likelihood of churning.
In brief, the main idea behind this project is to build a model with historical data from customers and assign a score of the likelihood of churning.
3.2 Data preparation¶
This session covered data obtention and some procedures of data preparation.
Commands, functions, and methods:
!wget– Linux shell command for downloading datapd.read.csv()– read csv filesdf.head()– take a look of the dataframedf.head().T– take a look of the transposed dataframedf.columns– retrieve column names of a dataframedf.columns.str.lower()– lowercase all the lettersdf.columns.str.replace(' ', '_')– replace the space separatordf.dtypes– retrieve data types of all seriesdf.index– retrive indices of a dataframepd.to_numeric()– convert a series values to numerical values. The errors=coerce argument allows making the transformation despite some encountered errors.df.fillna()– replace NAs with some value(df.x == "yes").astype(int)– convert x series of yes-no values to numerical values.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import urllib.request
url ='https://raw.githubusercontent.com/alexeygrigorev/mlbookcamp-code/master/chapter-03-churn-prediction/WA_Fn-UseC_-Telco-Customer-Churn.csv'
filename = 'data-week-3.csv'
urllib.request.urlretrieve(url, filename)
('data-week-3.csv', <http.client.HTTPMessage at 0x1ab9462e440>)
df = pd.read_csv('data-week-3.csv')
df
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | … | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | … | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | … | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.5 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | … | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | … | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | … | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 7038 | 6840-RESVB | Male | 0 | Yes | Yes | 24 | Yes | Yes | DSL | Yes | … | Yes | Yes | Yes | Yes | One year | Yes | Mailed check | 84.80 | 1990.5 | No |
| 7039 | 2234-XADUH | Female | 0 | Yes | Yes | 72 | Yes | Yes | Fiber optic | No | … | Yes | No | Yes | Yes | One year | Yes | Credit card (automatic) | 103.20 | 7362.9 | No |
| 7040 | 4801-JZAZL | Female | 0 | Yes | Yes | 11 | No | No phone service | DSL | Yes | … | No | No | No | No | Month-to-month | Yes | Electronic check | 29.60 | 346.45 | No |
| 7041 | 8361-LTMKD | Male | 1 | Yes | No | 4 | Yes | Yes | Fiber optic | No | … | No | No | No | No | Month-to-month | Yes | Mailed check | 74.40 | 306.6 | Yes |
| 7042 | 3186-AJIEK | Male | 0 | No | No | 66 | Yes | No | Fiber optic | Yes | … | Yes | Yes | Yes | Yes | Two year | Yes | Bank transfer (automatic) | 105.65 | 6844.5 | No |
7043 rows × 21 columns
Transposing the head() will easily show us the columns as rows so that we can see each column name.
df.head().T
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| customerID | 7590-VHVEG | 5575-GNVDE | 3668-QPYBK | 7795-CFOCW | 9237-HQITU |
| gender | Female | Male | Male | Male | Female |
| SeniorCitizen | 0 | 0 | 0 | 0 | 0 |
| Partner | Yes | No | No | No | No |
| Dependents | No | No | No | No | No |
| tenure | 1 | 34 | 2 | 45 | 2 |
| PhoneService | No | Yes | Yes | No | Yes |
| MultipleLines | No phone service | No | No | No phone service | No |
| InternetService | DSL | DSL | DSL | DSL | Fiber optic |
| OnlineSecurity | No | Yes | Yes | Yes | No |
| OnlineBackup | Yes | No | Yes | No | No |
| DeviceProtection | No | Yes | No | Yes | No |
| TechSupport | No | No | No | Yes | No |
| StreamingTV | No | No | No | No | No |
| StreamingMovies | No | No | No | No | No |
| Contract | Month-to-month | One year | Month-to-month | One year | Month-to-month |
| PaperlessBilling | Yes | No | Yes | No | Yes |
| PaymentMethod | Electronic check | Mailed check | Mailed check | Bank transfer (automatic) | Electronic check |
| MonthlyCharges | 29.85 | 56.95 | 53.85 | 42.3 | 70.7 |
| TotalCharges | 29.85 | 1889.5 | 108.15 | 1840.75 | 151.65 |
| Churn | No | No | Yes | No | Yes |
Again, we want to standardize the formatting of our column names and the str data within the dataframe. The top line takes care of the columns. The next lines assign a list of columns of datatype ‘object’ to the variable ‘categorical_columns’ and then we iterate through each of those columns to perform the lowercase and underscore replacements.
df.columns = df.columns.str.lower().str.replace(' ', '_')
categorical_columns = list(df.dtypes[df.dtypes == 'object'].index)
for c in categorical_columns:
df[c] = df[c].str.lower().str.replace(' ', '_')
df.head().T
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| customerid | 7590-vhveg | 5575-gnvde | 3668-qpybk | 7795-cfocw | 9237-hqitu |
| gender | female | male | male | male | female |
| seniorcitizen | 0 | 0 | 0 | 0 | 0 |
| partner | yes | no | no | no | no |
| dependents | no | no | no | no | no |
| tenure | 1 | 34 | 2 | 45 | 2 |
| phoneservice | no | yes | yes | no | yes |
| multiplelines | no_phone_service | no | no | no_phone_service | no |
| internetservice | dsl | dsl | dsl | dsl | fiber_optic |
| onlinesecurity | no | yes | yes | yes | no |
| onlinebackup | yes | no | yes | no | no |
| deviceprotection | no | yes | no | yes | no |
| techsupport | no | no | no | yes | no |
| streamingtv | no | no | no | no | no |
| streamingmovies | no | no | no | no | no |
| contract | month-to-month | one_year | month-to-month | one_year | month-to-month |
| paperlessbilling | yes | no | yes | no | yes |
| paymentmethod | electronic_check | mailed_check | mailed_check | bank_transfer_(automatic) | electronic_check |
| monthlycharges | 29.85 | 56.95 | 53.85 | 42.3 | 70.7 |
| totalcharges | 29.85 | 1889.5 | 108.15 | 1840.75 | 151.65 |
| churn | no | no | yes | no | yes |
df.dtypes
customerid object gender object seniorcitizen int64 partner object dependents object tenure int64 phoneservice object multiplelines object internetservice object onlinesecurity object onlinebackup object deviceprotection object techsupport object streamingtv object streamingmovies object contract object paperlessbilling object paymentmethod object monthlycharges float64 totalcharges object churn object dtype: object
We can see above that ‘totalcharges’ data is an object rather than some type of integer or float. Let’s try to convert it using the pandas method to_numeric
df.totalcharges
0 29.85
1 1889.5
2 108.15
3 1840.75
4 151.65
...
7038 1990.5
7039 7362.9
7040 346.45
7041 306.6
7042 6844.5
Name: totalcharges, Length: 7043, dtype: object
pd.to_numeric(df.totalcharges)
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) File ~\Desktop\DataScience\zoomcamp\env\lib\site-packages\pandas\_libs\lib.pyx:2315, in pandas._libs.lib.maybe_convert_numeric() ValueError: Unable to parse string "_" During handling of the above exception, another exception occurred: ValueError Traceback (most recent call last) Input In [9], in <cell line: 1>() ----> 1 pd.to_numeric(df.totalcharges) File ~\Desktop\DataScience\zoomcamp\env\lib\site-packages\pandas\core\tools\numeric.py:184, in to_numeric(arg, errors, downcast) 182 coerce_numeric = errors not in ("ignore", "raise") 183 try: --> 184 values, _ = lib.maybe_convert_numeric( 185 values, set(), coerce_numeric=coerce_numeric 186 ) 187 except (ValueError, TypeError): 188 if errors == "raise": File ~\Desktop\DataScience\zoomcamp\env\lib\site-packages\pandas\_libs\lib.pyx:2357, in pandas._libs.lib.maybe_convert_numeric() ValueError: Unable to parse string "_" at position 488
We can see that there are records that have a string in that column and not a number. We can modify this to ignore those items.
tc = pd.to_numeric(df.totalcharges, errors='coerce')
tc.isnull().sum()
11
There are 11 records with underscores in the ‘totalcharges’ column, lets look at those specific records.
df[tc.isnull()][['customerid', 'totalcharges']]
| customerid | totalcharges | |
|---|---|---|
| 488 | 4472-lvygi | _ |
| 753 | 3115-czmzd | _ |
| 936 | 5709-lvoeq | _ |
| 1082 | 4367-nuyao | _ |
| 1340 | 1371-dwpaz | _ |
| 3331 | 7644-omvmy | _ |
| 3826 | 3213-vvolg | _ |
| 4380 | 2520-sgtta | _ |
| 5218 | 2923-arzlg | _ |
| 6670 | 4075-wkniu | _ |
| 6754 | 2775-sefee | _ |
We are going to fill these records with zeros. We are choosing to do this for our own reasons, you will not always want to use zeros. Better options might be using the mean or median but for this analysis we are going to use zeros.
df.totalcharges = pd.to_numeric(df.totalcharges, errors='coerce')
df.totalcharges = df.totalcharges.fillna(0)
df[tc.isnull()][['customerid', 'totalcharges']]
| customerid | totalcharges | |
|---|---|---|
| 488 | 4472-lvygi | 0.0 |
| 753 | 3115-czmzd | 0.0 |
| 936 | 5709-lvoeq | 0.0 |
| 1082 | 4367-nuyao | 0.0 |
| 1340 | 1371-dwpaz | 0.0 |
| 3331 | 7644-omvmy | 0.0 |
| 3826 | 3213-vvolg | 0.0 |
| 4380 | 2520-sgtta | 0.0 |
| 5218 | 2923-arzlg | 0.0 |
| 6670 | 4075-wkniu | 0.0 |
| 6754 | 2775-sefee | 0.0 |
df.dtypes
customerid object gender object seniorcitizen int64 partner object dependents object tenure int64 phoneservice object multiplelines object internetservice object onlinesecurity object onlinebackup object deviceprotection object techsupport object streamingtv object streamingmovies object contract object paperlessbilling object paymentmethod object monthlycharges float64 totalcharges float64 churn object dtype: object
df.isnull().sum()
customerid 0 gender 0 seniorcitizen 0 partner 0 dependents 0 tenure 0 phoneservice 0 multiplelines 0 internetservice 0 onlinesecurity 0 onlinebackup 0 deviceprotection 0 techsupport 0 streamingtv 0 streamingmovies 0 contract 0 paperlessbilling 0 paymentmethod 0 monthlycharges 0 totalcharges 0 churn 0 dtype: int64
Let’s check some of the other variables.
df.churn
0 no
1 no
2 yes
3 no
4 yes
...
7038 no
7039 no
7040 no
7041 yes
7042 no
Name: churn, Length: 7043, dtype: object
Remember, for machine learning we need numbers, not str objects. Let’s convert ‘churn’, which will be our target variable, to an int depending on what is there. We will convert this and reassign it back to the same variable name.
(df.churn == 'yes').head()
0 False 1 False 2 True 3 False 4 True Name: churn, dtype: bool
df.churn = (df.churn == 'yes').astype(int)
df.churn.head()
0 0 1 0 2 1 3 0 4 1 Name: churn, dtype: int32
3.3 Setting up the validation framework¶
Splitting the dataset with Scikit-Learn.
Classes, functions, and methods:
train_test_split– Scikit-Learn class for splitting datasets. Linux shell command for downloading data. The random_state argument set a random seed for reproducibility purposes.df.reset_index(drop=True)– reset the indices of a dataframe and delete the previous ones.df.x.values– extract the values from x seriesdel df['x']– delete x series from a dataframe
from sklearn.model_selection import train_test_split
train_test_split?
#using this operator we can see details about the method
df_full_train, df_test = train_test_split(df, test_size=0.2, random_state=1)
len(df_full_train), len(df_test)
(5634, 1409)
df_train, df_val = train_test_split(df_full_train, test_size=len(df_test), random_state=1)
len(df_train), len(df_test), len(df_val)
(4225, 1409, 1409)
df_train = df_train.reset_index(drop=True)
df_val = df_val.reset_index(drop=True)
df_test = df_test.reset_index(drop=True)
y_train = df_train.churn.values
y_val = df_val.churn.values
y_test = df_test.churn.values
del df_train['churn']
del df_val['churn']
del df_test['churn']
3.4 EDA¶
The EDA for this project consisted of:
- Checking missing values
- Looking at the distribution of the target variable (churn)
- Looking at numerical and categorical variables
Functions and methods:
df.isnull().sum()– retunrs the number of null values in the dataframe.df.x.value_counts()returns the number of values for each category in x series. The normalize=True argument retrieves the percentage of each category. In this project, the mean of churn is equal to the churn rate obtained with the value_counts method.round(x, y)– round an x number with y decimal placesdf[x].nunique()– returns the number of unique values in x series
df_full_train = df_full_train.reset_index(drop=True)
df_full_train
| customerid | gender | seniorcitizen | partner | dependents | tenure | phoneservice | multiplelines | internetservice | onlinesecurity | … | deviceprotection | techsupport | streamingtv | streamingmovies | contract | paperlessbilling | paymentmethod | monthlycharges | totalcharges | churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5442-pptjy | male | 0 | yes | yes | 12 | yes | no | no | no_internet_service | … | no_internet_service | no_internet_service | no_internet_service | no_internet_service | two_year | no | mailed_check | 19.70 | 258.35 | 0 |
| 1 | 6261-rcvns | female | 0 | no | no | 42 | yes | no | dsl | yes | … | yes | yes | no | yes | one_year | no | credit_card_(automatic) | 73.90 | 3160.55 | 1 |
| 2 | 2176-osjuv | male | 0 | yes | no | 71 | yes | yes | dsl | yes | … | no | yes | no | no | two_year | no | bank_transfer_(automatic) | 65.15 | 4681.75 | 0 |
| 3 | 6161-erdgd | male | 0 | yes | yes | 71 | yes | yes | dsl | yes | … | yes | yes | yes | yes | one_year | no | electronic_check | 85.45 | 6300.85 | 0 |
| 4 | 2364-ufrom | male | 0 | no | no | 30 | yes | no | dsl | yes | … | no | yes | yes | no | one_year | no | electronic_check | 70.40 | 2044.75 | 0 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 5629 | 0781-lkxbr | male | 1 | no | no | 9 | yes | yes | fiber_optic | no | … | yes | no | yes | yes | month-to-month | yes | electronic_check | 100.50 | 918.60 | 1 |
| 5630 | 3507-gasnp | male | 0 | no | yes | 60 | yes | no | no | no_internet_service | … | no_internet_service | no_internet_service | no_internet_service | no_internet_service | two_year | no | mailed_check | 19.95 | 1189.90 | 0 |
| 5631 | 8868-wozgu | male | 0 | no | no | 28 | yes | yes | fiber_optic | no | … | yes | no | yes | yes | month-to-month | yes | electronic_check | 105.70 | 2979.50 | 1 |
| 5632 | 1251-krreg | male | 0 | no | no | 2 | yes | yes | dsl | no | … | no | no | no | no | month-to-month | yes | mailed_check | 54.40 | 114.10 | 1 |
| 5633 | 5840-nvdcg | female | 0 | yes | yes | 16 | yes | no | dsl | yes | … | no | yes | no | yes | two_year | no | bank_transfer_(automatic) | 68.25 | 1114.85 | 0 |
5634 rows × 21 columns
df_full_train.isnull().sum()
customerid 0 gender 0 seniorcitizen 0 partner 0 dependents 0 tenure 0 phoneservice 0 multiplelines 0 internetservice 0 onlinesecurity 0 onlinebackup 0 deviceprotection 0 techsupport 0 streamingtv 0 streamingmovies 0 contract 0 paperlessbilling 0 paymentmethod 0 monthlycharges 0 totalcharges 0 churn 0 dtype: int64
We have no missing values.
We can use the value_counts() method to see the number of customers that have ‘churned’. 1 = a churned customer, while 0 = no churn. We can add the normalize=True argument to calculate the percentage of churn, in this case it is 0.269968. We can also calculate the churn rate using the .mean() method. .mean works on binary classification columns.
df_full_train.churn.value_counts()
0 4113 1 1521 Name: churn, dtype: int64
df_full_train.churn.value_counts(normalize=True)
0 0.730032 1 0.269968 Name: churn, dtype: float64
global_churn_rate = df_full_train.churn.mean()
round(global_churn_rate, 2)
0.27
df_full_train.dtypes
customerid object gender object seniorcitizen int64 partner object dependents object tenure int64 phoneservice object multiplelines object internetservice object onlinesecurity object onlinebackup object deviceprotection object techsupport object streamingtv object streamingmovies object contract object paperlessbilling object paymentmethod object monthlycharges float64 totalcharges float64 churn int32 dtype: object
The ‘seniorcitizen’ is a binary column, 1 = senior citizen, 0 = not senior citizen so we don’t want to use that but we do want to use ‘tenure’, ‘monthlycharges’ and ‘totalcharges’.
numerical = ['tenure', 'monthlycharges', 'totalcharges']
Now that we have our numerical columns, we will remove those and create a list of categorical columns.
df_full_train.columns
Index(['customerid', 'gender', 'seniorcitizen', 'partner', 'dependents',
'tenure', 'phoneservice', 'multiplelines', 'internetservice',
'onlinesecurity', 'onlinebackup', 'deviceprotection', 'techsupport',
'streamingtv', 'streamingmovies', 'contract', 'paperlessbilling',
'paymentmethod', 'monthlycharges', 'totalcharges', 'churn'],
dtype='object')
categorical = ['gender', 'seniorcitizen', 'partner', 'dependents',
'phoneservice', 'multiplelines', 'internetservice',
'onlinesecurity', 'onlinebackup', 'deviceprotection', 'techsupport',
'streamingtv', 'streamingmovies', 'contract', 'paperlessbilling',
'paymentmethod']
We can look at the categorical columns in our dataframe.
df_full_train[categorical]
| gender | seniorcitizen | partner | dependents | phoneservice | multiplelines | internetservice | onlinesecurity | onlinebackup | deviceprotection | techsupport | streamingtv | streamingmovies | contract | paperlessbilling | paymentmethod | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | male | 0 | yes | yes | yes | no | no | no_internet_service | no_internet_service | no_internet_service | no_internet_service | no_internet_service | no_internet_service | two_year | no | mailed_check |
| 1 | female | 0 | no | no | yes | no | dsl | yes | yes | yes | yes | no | yes | one_year | no | credit_card_(automatic) |
| 2 | male | 0 | yes | no | yes | yes | dsl | yes | yes | no | yes | no | no | two_year | no | bank_transfer_(automatic) |
| 3 | male | 0 | yes | yes | yes | yes | dsl | yes | no | yes | yes | yes | yes | one_year | no | electronic_check |
| 4 | male | 0 | no | no | yes | no | dsl | yes | yes | no | yes | yes | no | one_year | no | electronic_check |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 5629 | male | 1 | no | no | yes | yes | fiber_optic | no | no | yes | no | yes | yes | month-to-month | yes | electronic_check |
| 5630 | male | 0 | no | yes | yes | no | no | no_internet_service | no_internet_service | no_internet_service | no_internet_service | no_internet_service | no_internet_service | two_year | no | mailed_check |
| 5631 | male | 0 | no | no | yes | yes | fiber_optic | no | yes | yes | no | yes | yes | month-to-month | yes | electronic_check |
| 5632 | male | 0 | no | no | yes | yes | dsl | no | yes | no | no | no | no | month-to-month | yes | mailed_check |
| 5633 | female | 0 | yes | yes | yes | no | dsl | yes | yes | no | yes | no | yes | two_year | no | bank_transfer_(automatic) |
5634 rows × 16 columns
We can also look and see the number of unique items in each column in our categorical colummns.
df_full_train[categorical].nunique()
gender 2 seniorcitizen 2 partner 2 dependents 2 phoneservice 2 multiplelines 3 internetservice 3 onlinesecurity 3 onlinebackup 3 deviceprotection 3 techsupport 3 streamingtv 3 streamingmovies 3 contract 3 paperlessbilling 2 paymentmethod 4 dtype: int64
3.5 Feature importance: Churn rate and risk ratio¶
- Churn rate: Difference between mean of the target variable and mean of categories for a feature. If this difference is greater than 0, it means that the category is less likely to churn, and if the difference is lower than 0, the group is more likely to churn. The larger differences are indicators that a variable is more important than others.
- Risk ratio: Ratio between mean of categories for a feature and mean of the target variable. If this ratio is greater than 1, the category is more likely to churn, and if the ratio is lower than 1, the category is less likely to churn. It expresses the feature importance in relative terms.
Functions and methods:
df.groupby('x').y.agg([mean()])– returns a datframe with mean of y series grouped by x seriesdisplay(x)displays an output in the cell of a jupyter notebook.
Churn rate¶
We can calculate some importance of the difference of churn from the global, where more likely to churn < 0 > less likely to churn in a global – group scenario
df_full_train.head()
| customerid | gender | seniorcitizen | partner | dependents | tenure | phoneservice | multiplelines | internetservice | onlinesecurity | … | deviceprotection | techsupport | streamingtv | streamingmovies | contract | paperlessbilling | paymentmethod | monthlycharges | totalcharges | churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5442-pptjy | male | 0 | yes | yes | 12 | yes | no | no | no_internet_service | … | no_internet_service | no_internet_service | no_internet_service | no_internet_service | two_year | no | mailed_check | 19.70 | 258.35 | 0 |
| 1 | 6261-rcvns | female | 0 | no | no | 42 | yes | no | dsl | yes | … | yes | yes | no | yes | one_year | no | credit_card_(automatic) | 73.90 | 3160.55 | 1 |
| 2 | 2176-osjuv | male | 0 | yes | no | 71 | yes | yes | dsl | yes | … | no | yes | no | no | two_year | no | bank_transfer_(automatic) | 65.15 | 4681.75 | 0 |
| 3 | 6161-erdgd | male | 0 | yes | yes | 71 | yes | yes | dsl | yes | … | yes | yes | yes | yes | one_year | no | electronic_check | 85.45 | 6300.85 | 0 |
| 4 | 2364-ufrom | male | 0 | no | no | 30 | yes | no | dsl | yes | … | no | yes | yes | no | one_year | no | electronic_check | 70.40 | 2044.75 | 0 |
5 rows × 21 columns
Our dataset may have different churn rates for different groups such as male or female, dependents or not.
churn_female = df_full_train[df_full_train.gender == 'female'].churn.mean()
churn_female
0.27682403433476394
churn_male = df_full_train[df_full_train.gender == 'male'].churn.mean()
churn_male
0.2632135306553911
global_churn = df_full_train.churn.mean()
global_churn
0.26996805111821087
There is not much difference for male or female from the global churn mean.
churn_partner = df_full_train[df_full_train.partner == 'yes'].churn.mean()
churn_partner
0.20503330866025166
churn_no_partner = df_full_train[df_full_train.partner == 'no'].churn.mean()
churn_no_partner
0.3298090040927694
The difference in churn rate for people with or without a partner is fairly significant. There is roughly a 6% difference between the global churn rate and the churn rate of people with a partner. This tells us that the partner variable will be more predictive of the churn rate than will gender.
global_churn - churn_partner
0.06493474245795922
Risk ratio¶
The risk ratio is measured by dividing our variable rates by our global churn rate. We see that the ‘churn_no_partner’ has a higher risk of churn than ‘churn_partner’. more likely to churn > 1 > less likely to churn
churn_no_partner / global_churn
1.2216593879412643
churn_partner / global_churn
0.7594724924338315
We are doing a relative risk caluclation for groups against the global churn rate.
Here is a SQL example:
SELECT
gender,
AVG(churn),
AVG(churn) - global_churn AS diff,
AVG(churn) / global_churn AS risk
FROM
data
GROUP BY
gender;df_full_train.groupby('gender').churn.mean()
gender female 0.276824 male 0.263214 Name: churn, dtype: float64
We can do what we have done above with some more simple code below. And we can see the different numbers in our small df_group dataframe.
df_group = df_full_train.groupby('gender').churn.agg(['mean', 'count'])
df_group['diff'] = df_group['mean'] - global_churn
df_group['risk'] = df_group['mean'] / global_churn
df_group
| mean | count | diff | risk | |
|---|---|---|---|---|
| gender | ||||
| female | 0.276824 | 2796 | 0.006856 | 1.025396 |
| male | 0.263214 | 2838 | -0.006755 | 0.974980 |
We want to do the same thing with ALL of our categorical values. The df_group will not do a print inside of a function so we will import the display function from the IPython.display library and implement it.
from IPython.display import display
for c in categorical:
print(c)
df_group = df_full_train.groupby(c).churn.agg(['mean', 'count'])
df_group['diff'] = df_group['mean'] - global_churn
df_group['risk'] = df_group['mean'] / global_churn
display(df_group)
print()
print()
gender
| mean | count | diff | risk | |
|---|---|---|---|---|
| gender | ||||
| female | 0.276824 | 2796 | 0.006856 | 1.025396 |
| male | 0.263214 | 2838 | -0.006755 | 0.974980 |
seniorcitizen
| mean | count | diff | risk | |
|---|---|---|---|---|
| seniorcitizen | ||||
| 0 | 0.242270 | 4722 | -0.027698 | 0.897403 |
| 1 | 0.413377 | 912 | 0.143409 | 1.531208 |
partner
| mean | count | diff | risk | |
|---|---|---|---|---|
| partner | ||||
| no | 0.329809 | 2932 | 0.059841 | 1.221659 |
| yes | 0.205033 | 2702 | -0.064935 | 0.759472 |
dependents
| mean | count | diff | risk | |
|---|---|---|---|---|
| dependents | ||||
| no | 0.313760 | 3968 | 0.043792 | 1.162212 |
| yes | 0.165666 | 1666 | -0.104302 | 0.613651 |
phoneservice
| mean | count | diff | risk | |
|---|---|---|---|---|
| phoneservice | ||||
| no | 0.241316 | 547 | -0.028652 | 0.893870 |
| yes | 0.273049 | 5087 | 0.003081 | 1.011412 |
multiplelines
| mean | count | diff | risk | |
|---|---|---|---|---|
| multiplelines | ||||
| no | 0.257407 | 2700 | -0.012561 | 0.953474 |
| no_phone_service | 0.241316 | 547 | -0.028652 | 0.893870 |
| yes | 0.290742 | 2387 | 0.020773 | 1.076948 |
internetservice
| mean | count | diff | risk | |
|---|---|---|---|---|
| internetservice | ||||
| dsl | 0.192347 | 1934 | -0.077621 | 0.712482 |
| fiber_optic | 0.425171 | 2479 | 0.155203 | 1.574895 |
| no | 0.077805 | 1221 | -0.192163 | 0.288201 |
onlinesecurity
| mean | count | diff | risk | |
|---|---|---|---|---|
| onlinesecurity | ||||
| no | 0.420921 | 2801 | 0.150953 | 1.559152 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.153226 | 1612 | -0.116742 | 0.567570 |
onlinebackup
| mean | count | diff | risk | |
|---|---|---|---|---|
| onlinebackup | ||||
| no | 0.404323 | 2498 | 0.134355 | 1.497672 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.217232 | 1915 | -0.052736 | 0.804660 |
deviceprotection
| mean | count | diff | risk | |
|---|---|---|---|---|
| deviceprotection | ||||
| no | 0.395875 | 2473 | 0.125907 | 1.466379 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.230412 | 1940 | -0.039556 | 0.853480 |
techsupport
| mean | count | diff | risk | |
|---|---|---|---|---|
| techsupport | ||||
| no | 0.418914 | 2781 | 0.148946 | 1.551717 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.159926 | 1632 | -0.110042 | 0.592390 |
streamingtv
| mean | count | diff | risk | |
|---|---|---|---|---|
| streamingtv | ||||
| no | 0.342832 | 2246 | 0.072864 | 1.269897 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.302723 | 2167 | 0.032755 | 1.121328 |
streamingmovies
| mean | count | diff | risk | |
|---|---|---|---|---|
| streamingmovies | ||||
| no | 0.338906 | 2213 | 0.068938 | 1.255358 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.307273 | 2200 | 0.037305 | 1.138182 |
contract
| mean | count | diff | risk | |
|---|---|---|---|---|
| contract | ||||
| month-to-month | 0.431701 | 3104 | 0.161733 | 1.599082 |
| one_year | 0.120573 | 1186 | -0.149395 | 0.446621 |
| two_year | 0.028274 | 1344 | -0.241694 | 0.104730 |
paperlessbilling
| mean | count | diff | risk | |
|---|---|---|---|---|
| paperlessbilling | ||||
| no | 0.172071 | 2313 | -0.097897 | 0.637375 |
| yes | 0.338151 | 3321 | 0.068183 | 1.252560 |
paymentmethod
| mean | count | diff | risk | |
|---|---|---|---|---|
| paymentmethod | ||||
| bank_transfer_(automatic) | 0.168171 | 1219 | -0.101797 | 0.622928 |
| credit_card_(automatic) | 0.164339 | 1217 | -0.105630 | 0.608733 |
| electronic_check | 0.455890 | 1893 | 0.185922 | 1.688682 |
| mailed_check | 0.193870 | 1305 | -0.076098 | 0.718121 |
3.6 Feature importance: Mutual information¶
Mutual information is a concept from information theory, which measures how much we can learn about one variable if we know the value of another. In this project, we can think of this as how much do we learn about churn if we have the information from a particular feature. So, it is a measure of the importance of a categorical variable.
Classes, functions, and methods:
mutual_info_score(x, y)– Scikit-Learn class for calculating the mutual information between the x target variable and y feature.df[x].apply(y)– apply a y function to the x series of the df dataframe.df.sort_values(ascending=False).to_frame(name='x')– sort values in an ascending order and called the column as x.
from sklearn.metrics import mutual_info_score
We can use the mutual_info_score method from sklearn to caculate the mutual information score between two variables. Our target variable is ‘churn’ and we want to see, for instance, how much the variable ‘contract’ affects the ‘churn’ rate. The higher the number the more it is a predictor of churn.
mutual_info_score(df_full_train.churn, df_full_train.contract)
0.0983203874041556
mutual_info_score(df_full_train.churn, df_full_train.gender)
0.0001174846211139946
def mutual_info_churn_score(series):
return mutual_info_score(df_full_train.churn, series)
df_full_train[categorical].apply(mutual_info_churn_score)
gender 0.000117 seniorcitizen 0.009410 partner 0.009968 dependents 0.012346 phoneservice 0.000229 multiplelines 0.000857 internetservice 0.055868 onlinesecurity 0.063085 onlinebackup 0.046923 deviceprotection 0.043453 techsupport 0.061032 streamingtv 0.031853 streamingmovies 0.031581 contract 0.098320 paperlessbilling 0.017589 paymentmethod 0.043210 dtype: float64
mi = df_full_train[categorical].apply(mutual_info_churn_score)
mi.sort_values(ascending=False)
contract 0.098320 onlinesecurity 0.063085 techsupport 0.061032 internetservice 0.055868 onlinebackup 0.046923 deviceprotection 0.043453 paymentmethod 0.043210 streamingtv 0.031853 streamingmovies 0.031581 paperlessbilling 0.017589 dependents 0.012346 partner 0.009968 seniorcitizen 0.009410 multiplelines 0.000857 phoneservice 0.000229 gender 0.000117 dtype: float64
We can see that ‘contract’ is the most import predictor of churn and ‘gender’ is least predictive.
3.7 Feature importance: Correlation¶
How about numerical columns?
Correlation coefficient measures the degree of dependency between two variables. This value is negative if one variable grows while the other decreases, and it is positive if both variables increase. Depending on its size, the dependency between both variables could be low, moderate, or strong. It allows measuring the importance of numerical variables.
Functions and methods:
df[x].corrwith(y)– returns the correlation between x and y series.
- Correlation coefficient – https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
df_full_train.tenure.max()
72
df_full_train[numerical]
| tenure | monthlycharges | totalcharges | |
|---|---|---|---|
| 0 | 12 | 19.70 | 258.35 |
| 1 | 42 | 73.90 | 3160.55 |
| 2 | 71 | 65.15 | 4681.75 |
| 3 | 71 | 85.45 | 6300.85 |
| 4 | 30 | 70.40 | 2044.75 |
| … | … | … | … |
| 5629 | 9 | 100.50 | 918.60 |
| 5630 | 60 | 19.95 | 1189.90 |
| 5631 | 28 | 105.70 | 2979.50 |
| 5632 | 2 | 54.40 | 114.10 |
| 5633 | 16 | 68.25 | 1114.85 |
5634 rows × 3 columns
df_full_train[numerical].corrwith(df_full_train.churn)
tenure -0.351885 monthlycharges 0.196805 totalcharges -0.196353 dtype: float64
df_full_train[numerical].corrwith(df_full_train.churn).abs()
tenure 0.351885 monthlycharges 0.196805 totalcharges 0.196353 dtype: float64
We can calculate the correlation with one numerical column to the churn rate using corrwith. We can see that ‘tenure’ is negatively correlated with ‘churn’. This tells us that the longer a customer is with the company the less churn rate there is. ‘totalcharges’ is also positively correlated with ‘tenure’, the longer a customer is with the company the higher their ‘totalcharges’ will be.
Now, let’s check some churn rates with various variables that are grouped by time.
df_full_train[df_full_train.tenure <= 2].churn.mean()
0.5953420669577875
For customers that are with the company for 2 or less months, the churn rate is 60%.
df_full_train[df_full_train.tenure > 2].churn.mean()
0.22478269658378816
For customers that are with the company for more than 2 months, the churn rate is 22%.
df_full_train[(df_full_train.tenure > 2) & (df_full_train.tenure <= 12) ].churn.mean()
0.3994413407821229
For customers that are with the company for greater than 2 months but less than 12 months, the churn rate is 40%.
df_full_train[df_full_train.tenure > 12].churn.mean()
0.17634908339788277
For customers that are with the company greater than 1 year, the churn rate is 18%.
df_full_train[df_full_train.monthlycharges <= 20].churn.mean()
0.08795411089866156
df_full_train[(df_full_train.monthlycharges > 20) & (df_full_train.monthlycharges <= 50) ].churn.mean()
0.18340943683409436
df_full_train[df_full_train.monthlycharges > 12].churn.mean()
0.26996805111821087
We can see that ‘tenure’ is negatively correlated with ‘churn’ and ‘monthlycharges’ is positively correlated with ‘churn’.
3.8 One-hot encoding¶
One-Hot Encoding allows encoding categorical variables in numerical ones. This method represents each category of a variable as one column, and a 1 is assigned if the value belongs to the category or 0 otherwise.
Classes, functions, and methods:
df[x].to_dict(oriented='records')– convert x series to dictionaries, oriented by rows.DictVectorizer().fit_transform(x)– Scikit-Learn class for converting x dictionaries into a sparse matrix, and in this way doing the one-hot encoding. It does not affect the numerical variables.DictVectorizer().get_feature_names()– returns the names of the columns in the sparse matrix.
from sklearn.feature_extraction import DictVectorizer
Let’s take a look at a small dataframe of the columns ‘gender’ and ‘contract’.
df_train[['gender', 'contract']].iloc[:100]
| gender | contract | |
|---|---|---|
| 0 | female | two_year |
| 1 | male | month-to-month |
| 2 | female | month-to-month |
| 3 | female | month-to-month |
| 4 | female | two_year |
| … | … | … |
| 95 | male | one_year |
| 96 | female | month-to-month |
| 97 | male | month-to-month |
| 98 | male | one_year |
| 99 | male | month-to-month |
100 rows × 2 columns
We can take the above dataframe and turn it into a dictionary that is oriented to records, or rows in the dataframe.
dicts = df_train[['gender', 'contract']].iloc[:100].to_dict('record')
dicts
C:\Users\daver\AppData\Local\Temp\ipykernel_13448\7526895.py:1: FutureWarning: Using short name for 'orient' is deprecated. Only the options: ('dict', list, 'series', 'split', 'records', 'index') will be used in a future version. Use one of the above to silence this warning.
dicts = df_train[['gender', 'contract']].iloc[:100].to_dict('record')
[{'gender': 'female', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'two_year'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'one_year'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'two_year'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'one_year'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'two_year'},
{'gender': 'male', 'contract': 'one_year'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'one_year'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'one_year'},
{'gender': 'female', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'month-to-month'},
{'gender': 'male', 'contract': 'one_year'},
{'gender': 'male', 'contract': 'month-to-month'}]
Now we need to use the DictVectorizer method to turn our dictionary into a vector, so we first create an instance and assign it to variable ‘dv’, then we do the conversion using .fits method.
dv = DictVectorizer()
We can see above that transform is forcing us to use a ‘Compressed Sparse Row’ format, which we do not want to use and we can specify that we don’t want to use that by adding the argument ‘sparse=False’.
dv = DictVectorizer(sparse=False)
dv.fit(dicts)
DictVectorizer(sparse=False)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DictVectorizer(sparse=False)
dv.get_feature_names()
C:\Users\daver\Desktop\DataScience\zoomcamp\env\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead. warnings.warn(msg, category=FutureWarning)
['contract=month-to-month', 'contract=one_year', 'contract=two_year', 'gender=female', 'gender=male']
Using get_feature_names() we generate a list of the feature names that correspond with the columns below. We can see that the first column in our array below is the ‘contract=month-to-month’ feature.
dv.transform(dicts)
array([[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 1., 0.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 1., 0.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 1., 0.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[1., 0., 0., 1., 0.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 1., 0.],
[0., 1., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 1., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[0., 1., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[0., 1., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[1., 0., 0., 0., 1.]])
Now let’s create a dictionary that contains all the columns and all the records.
train_dicts = df_train[categorical + numerical].to_dict('records')
train_dicts[0]
{'gender': 'female',
'seniorcitizen': 0,
'partner': 'yes',
'dependents': 'yes',
'phoneservice': 'yes',
'multiplelines': 'yes',
'internetservice': 'fiber_optic',
'onlinesecurity': 'yes',
'onlinebackup': 'yes',
'deviceprotection': 'yes',
'techsupport': 'yes',
'streamingtv': 'yes',
'streamingmovies': 'yes',
'contract': 'two_year',
'paperlessbilling': 'yes',
'paymentmethod': 'electronic_check',
'tenure': 72,
'monthlycharges': 115.5,
'totalcharges': 8425.15}
dv.fit(train_dicts)
DictVectorizer(sparse=False)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DictVectorizer(sparse=False)
dv.transform(train_dicts)
array([[0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 1.00000e+00,
7.20000e+01, 8.42515e+03],
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
1.00000e+01, 1.02155e+03],
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
5.00000e+00, 4.13650e+02],
...,
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 1.00000e+00,
2.00000e+00, 1.90050e+02],
[0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 0.00000e+00,
2.70000e+01, 7.61950e+02],
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
9.00000e+00, 7.51650e+02]])
dv.get_feature_names_out()
array(['contract=month-to-month', 'contract=one_year',
'contract=two_year', 'dependents=no', 'dependents=yes',
'deviceprotection=no', 'deviceprotection=no_internet_service',
'deviceprotection=yes', 'gender=female', 'gender=male',
'internetservice=dsl', 'internetservice=fiber_optic',
'internetservice=no', 'monthlycharges', 'multiplelines=no',
'multiplelines=no_phone_service', 'multiplelines=yes',
'onlinebackup=no', 'onlinebackup=no_internet_service',
'onlinebackup=yes', 'onlinesecurity=no',
'onlinesecurity=no_internet_service', 'onlinesecurity=yes',
'paperlessbilling=no', 'paperlessbilling=yes', 'partner=no',
'partner=yes', 'paymentmethod=bank_transfer_(automatic)',
'paymentmethod=credit_card_(automatic)',
'paymentmethod=electronic_check', 'paymentmethod=mailed_check',
'phoneservice=no', 'phoneservice=yes', 'seniorcitizen',
'streamingmovies=no', 'streamingmovies=no_internet_service',
'streamingmovies=yes', 'streamingtv=no',
'streamingtv=no_internet_service', 'streamingtv=yes',
'techsupport=no', 'techsupport=no_internet_service',
'techsupport=yes', 'tenure', 'totalcharges'], dtype=object)
We can incorporate fit and transform together in one statement and assign it to our X_train variable.
X_train = dv.fit_transform(train_dicts)
X_train.shape
(4225, 45)
X_train
array([[0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 1.00000e+00,
7.20000e+01, 8.42515e+03],
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
1.00000e+01, 1.02155e+03],
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
5.00000e+00, 4.13650e+02],
...,
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 1.00000e+00,
2.00000e+00, 1.90050e+02],
[0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 0.00000e+00,
2.70000e+01, 7.61950e+02],
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
9.00000e+00, 7.51650e+02]])
We also need to fit and transform our validation dataset.
val_dicts = df_val[categorical + numerical].to_dict('records')
val_dicts[0]
{'gender': 'male',
'seniorcitizen': 0,
'partner': 'yes',
'dependents': 'yes',
'phoneservice': 'yes',
'multiplelines': 'no',
'internetservice': 'dsl',
'onlinesecurity': 'yes',
'onlinebackup': 'no',
'deviceprotection': 'yes',
'techsupport': 'yes',
'streamingtv': 'no',
'streamingmovies': 'yes',
'contract': 'two_year',
'paperlessbilling': 'yes',
'paymentmethod': 'credit_card_(automatic)',
'tenure': 71,
'monthlycharges': 70.85,
'totalcharges': 4973.4}
And we just need to use transform on the validation dataset and not fit.
X_val = dv.transform(val_dicts)
X_val.shape
(1409, 45)
Now we can put that all in one block.
dv = DictVectorizer(sparse=False)
train_dicts = df_train[categorical + numerical].to_dict('records')
X_train = dv.fit_transform(train_dicts)
val_dicts = df_val[categorical + numerical].to_dict('records')
X_val = dv.transform(val_dicts)
3.9 Logistic regression¶
In general, supervised models follow can be represented with this formula:
Depending on what is the type of target variable, the supervised task can be regression or classification (binary or multiclass). Binary classification tasks can have negative (0) or positive (1) target values. The output of these models is the probability of xi belonging to the positive class.
Logistic regression is similar to linear regression because both models take into account the bias term and weighted sum of features. The difference between these models is that the output of linear regression is a real number, while logistic regression outputs a value between zero and one, applying the sigmoid function to the linear regression formula.


def sigmoid(z):
return 1 / (1 + np.exp(-z))
z = np.linspace(-7, 7, 51)
z
array([-7.0000000e+00, -6.7200000e+00, -6.4400000e+00, -6.1600000e+00,
-5.8800000e+00, -5.6000000e+00, -5.3200000e+00, -5.0400000e+00,
-4.7600000e+00, -4.4800000e+00, -4.2000000e+00, -3.9200000e+00,
-3.6400000e+00, -3.3600000e+00, -3.0800000e+00, -2.8000000e+00,
-2.5200000e+00, -2.2400000e+00, -1.9600000e+00, -1.6800000e+00,
-1.4000000e+00, -1.1200000e+00, -8.4000000e-01, -5.6000000e-01,
-2.8000000e-01, 8.8817842e-16, 2.8000000e-01, 5.6000000e-01,
8.4000000e-01, 1.1200000e+00, 1.4000000e+00, 1.6800000e+00,
1.9600000e+00, 2.2400000e+00, 2.5200000e+00, 2.8000000e+00,
3.0800000e+00, 3.3600000e+00, 3.6400000e+00, 3.9200000e+00,
4.2000000e+00, 4.4800000e+00, 4.7600000e+00, 5.0400000e+00,
5.3200000e+00, 5.6000000e+00, 5.8800000e+00, 6.1600000e+00,
6.4400000e+00, 6.7200000e+00, 7.0000000e+00])
sigmoid(z)
array([9.11051194e-04, 1.20508423e-03, 1.59386223e-03, 2.10780106e-03,
2.78699622e-03, 3.68423990e-03, 4.86893124e-03, 6.43210847e-03,
8.49286285e-03, 1.12064063e-02, 1.47740317e-02, 1.94550846e-02,
2.55807883e-02, 3.35692233e-02, 4.39398154e-02, 5.73241759e-02,
7.44679452e-02, 9.62155417e-02, 1.23467048e-01, 1.57095469e-01,
1.97816111e-01, 2.46011284e-01, 3.01534784e-01, 3.63547460e-01,
4.30453776e-01, 5.00000000e-01, 5.69546224e-01, 6.36452540e-01,
6.98465216e-01, 7.53988716e-01, 8.02183889e-01, 8.42904531e-01,
8.76532952e-01, 9.03784458e-01, 9.25532055e-01, 9.42675824e-01,
9.56060185e-01, 9.66430777e-01, 9.74419212e-01, 9.80544915e-01,
9.85225968e-01, 9.88793594e-01, 9.91507137e-01, 9.93567892e-01,
9.95131069e-01, 9.96315760e-01, 9.97213004e-01, 9.97892199e-01,
9.98406138e-01, 9.98794916e-01, 9.99088949e-01])
plt.plot(z, sigmoid(z))
[<matplotlib.lines.Line2D at 0x1ab99b815d0>]

def linear_regression(xi):
result = w0
for j in range(len(w)):
result = result + xi[j] * w[j]
return result
A review above of our linear regression function, the logistic regression function is very similar.
def logistic_regression(xi):
for j in range(len(w)):
score = score + xi[j] * w[j]
result = sigmoid(score)
return result
3.10 Training logistic regression with Scikit-Learn¶
This video was about training a logistic regression model with Scikit-Learn, applying it to the validation dataset, and calculating its accuracy.
Classes, functions, and methods:
LogisticRegression().fit_transform(x)– Scikit-Learn class for calculating the logistic regression model.LogisticRegression().coef_[0]– returns the coeffcients or weights of the LR modelLogisticRegression().intercept_[0]– returns the bias or intercept of the LR modelLogisticRegression().predict[x]– make predictions on the x datasetLogisticRegression().predict_proba[x]– make predictions on the x dataset, and returns two columns with their probabilities for the two categories – soft predictions
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
LogisticRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression()
We can see the bias term that will be added to each record.
model.intercept_[0]
-0.10896197525251598
We can see the weights that will be applied to each feature column.
model.coef_[0].round(3)
array([ 0.475, -0.175, -0.408, -0.03 , -0.078, 0.063, -0.089, -0.081,
-0.034, -0.073, -0.336, 0.317, -0.089, 0.004, -0.258, 0.141,
0.009, 0.063, -0.089, -0.081, 0.266, -0.089, -0.285, -0.231,
0.124, -0.166, 0.058, -0.087, -0.032, 0.071, -0.059, 0.141,
-0.249, 0.216, -0.121, -0.089, 0.102, -0.071, -0.089, 0.052,
0.213, -0.089, -0.232, -0.07 , 0. ])
We can create hard predictions. Below we can see that the model.predict method will return a 1 = churn, a 0 = no churn. But we don’t know that actual probability.
model.predict(X_train)
array([0, 1, 1, ..., 1, 0, 1])
Below, we have created soft predictions with a probability of churning. We have a 2 dimensional array with two proabilities. The left hand side is the probability of no churn and the right hand side is the probability of churn. We really only need one side as bothsides sum to 1.
model.predict_proba(X_train)
array([[0.90472747, 0.09527253],
[0.32048871, 0.67951129],
[0.36613987, 0.63386013],
...,
[0.46831654, 0.53168346],
[0.95736084, 0.04263916],
[0.30101514, 0.69898486]])
Below will create an array with just the second group of numbers that is our soft prediction, i.e. 0.67951129 is a 68% probability of churn.
model.predict_proba(X_train)[:, 1]
array([0.09527253, 0.67951129, 0.63386013, ..., 0.53168346, 0.04263916,
0.69898486])
y_pred = model.predict_proba(X_val)[:, 1]
y_pred
array([0.00899416, 0.20483208, 0.21257239, ..., 0.13641188, 0.79993906,
0.83756648])
Now we can make some predictions using the y_pred about if a client may potentially churn or not.
y_pred >= 0.5
array([False, False, False, ..., False, True, True])
churn_decision = y_pred >= 0.5
Now we can choose the customers by customerid that have a higher probability of churning than the rest of the customers. Now that we have identified those customers now we can tailor email promotions or ads or product discounts in order to reduce churn with those customers.
df_val[churn_decision].customerid
3 8433-wxgna
8 3440-jpscl
11 2637-fkfsy
12 7228-omtpn
19 6711-fldfb
...
1397 5976-jcjrh
1398 2034-cgrhz
1399 5276-kqwhg
1407 6521-yytyi
1408 3049-solay
Name: customerid, Length: 311, dtype: object
Let’s calculate the accuracy of our model.
churn_decision.astype(int)
array([0, 0, 0, ..., 0, 1, 1])
(y_val == churn_decision).mean()
0.8034066713981547
We can see above that about 80% of our predictions matched the original dataset.
df_pred = pd.DataFrame()
df_pred['probability'] = y_pred
df_pred['prediction'] = churn_decision.astype(int)
df_pred['actual'] = y_val
df_pred
| probability | prediction | actual | |
|---|---|---|---|
| 0 | 0.008994 | 0 | 0 |
| 1 | 0.204832 | 0 | 0 |
| 2 | 0.212572 | 0 | 0 |
| 3 | 0.543185 | 1 | 1 |
| 4 | 0.214111 | 0 | 0 |
| … | … | … | … |
| 1404 | 0.314004 | 0 | 0 |
| 1405 | 0.039366 | 0 | 1 |
| 1406 | 0.136412 | 0 | 0 |
| 1407 | 0.799939 | 1 | 1 |
| 1408 | 0.837566 | 1 | 1 |
1409 rows × 3 columns
df_pred['correct'] = df_pred.prediction == df_pred.actual
df_pred
| probability | prediction | actual | correct | |
|---|---|---|---|---|
| 0 | 0.008994 | 0 | 0 | True |
| 1 | 0.204832 | 0 | 0 | True |
| 2 | 0.212572 | 0 | 0 | True |
| 3 | 0.543185 | 1 | 1 | True |
| 4 | 0.214111 | 0 | 0 | True |
| … | … | … | … | … |
| 1404 | 0.314004 | 0 | 0 | True |
| 1405 | 0.039366 | 0 | 1 | False |
| 1406 | 0.136412 | 0 | 0 | True |
| 1407 | 0.799939 | 1 | 1 | True |
| 1408 | 0.837566 | 1 | 1 | True |
1409 rows × 4 columns
df_pred.correct.mean()
0.8034066713981547
3.11 Model interpretation¶
This video was about the interpretation of coefficients, and training a model with fewer features.
In the formula of the logistic regression model, only one of the one-hot encoded categories is multiplied by 1, and the other by 0. In this way, we only consider the appropriate category for each categorical feature.
Classes, functions, and methods:
zip(x,y)– returns a new list with elements from x joined with their corresponding elements on y
dv.get_feature_names_out()
array(['contract=month-to-month', 'contract=one_year',
'contract=two_year', 'dependents=no', 'dependents=yes',
'deviceprotection=no', 'deviceprotection=no_internet_service',
'deviceprotection=yes', 'gender=female', 'gender=male',
'internetservice=dsl', 'internetservice=fiber_optic',
'internetservice=no', 'monthlycharges', 'multiplelines=no',
'multiplelines=no_phone_service', 'multiplelines=yes',
'onlinebackup=no', 'onlinebackup=no_internet_service',
'onlinebackup=yes', 'onlinesecurity=no',
'onlinesecurity=no_internet_service', 'onlinesecurity=yes',
'paperlessbilling=no', 'paperlessbilling=yes', 'partner=no',
'partner=yes', 'paymentmethod=bank_transfer_(automatic)',
'paymentmethod=credit_card_(automatic)',
'paymentmethod=electronic_check', 'paymentmethod=mailed_check',
'phoneservice=no', 'phoneservice=yes', 'seniorcitizen',
'streamingmovies=no', 'streamingmovies=no_internet_service',
'streamingmovies=yes', 'streamingtv=no',
'streamingtv=no_internet_service', 'streamingtv=yes',
'techsupport=no', 'techsupport=no_internet_service',
'techsupport=yes', 'tenure', 'totalcharges'], dtype=object)
model.coef_[0].round(3)
array([ 0.475, -0.175, -0.408, -0.03 , -0.078, 0.063, -0.089, -0.081,
-0.034, -0.073, -0.336, 0.317, -0.089, 0.004, -0.258, 0.141,
0.009, 0.063, -0.089, -0.081, 0.266, -0.089, -0.285, -0.231,
0.124, -0.166, 0.058, -0.087, -0.032, 0.071, -0.059, 0.141,
-0.249, 0.216, -0.121, -0.089, 0.102, -0.071, -0.089, 0.052,
0.213, -0.089, -0.232, -0.07 , 0. ])
dict(zip(dv.get_feature_names_out(), model.coef_[0].round(3)))
{'contract=month-to-month': 0.475,
'contract=one_year': -0.175,
'contract=two_year': -0.408,
'dependents=no': -0.03,
'dependents=yes': -0.078,
'deviceprotection=no': 0.063,
'deviceprotection=no_internet_service': -0.089,
'deviceprotection=yes': -0.081,
'gender=female': -0.034,
'gender=male': -0.073,
'internetservice=dsl': -0.336,
'internetservice=fiber_optic': 0.317,
'internetservice=no': -0.089,
'monthlycharges': 0.004,
'multiplelines=no': -0.258,
'multiplelines=no_phone_service': 0.141,
'multiplelines=yes': 0.009,
'onlinebackup=no': 0.063,
'onlinebackup=no_internet_service': -0.089,
'onlinebackup=yes': -0.081,
'onlinesecurity=no': 0.266,
'onlinesecurity=no_internet_service': -0.089,
'onlinesecurity=yes': -0.285,
'paperlessbilling=no': -0.231,
'paperlessbilling=yes': 0.124,
'partner=no': -0.166,
'partner=yes': 0.058,
'paymentmethod=bank_transfer_(automatic)': -0.087,
'paymentmethod=credit_card_(automatic)': -0.032,
'paymentmethod=electronic_check': 0.071,
'paymentmethod=mailed_check': -0.059,
'phoneservice=no': 0.141,
'phoneservice=yes': -0.249,
'seniorcitizen': 0.216,
'streamingmovies=no': -0.121,
'streamingmovies=no_internet_service': -0.089,
'streamingmovies=yes': 0.102,
'streamingtv=no': -0.071,
'streamingtv=no_internet_service': -0.089,
'streamingtv=yes': 0.052,
'techsupport=no': 0.213,
'techsupport=no_internet_service': -0.089,
'techsupport=yes': -0.232,
'tenure': -0.07,
'totalcharges': 0.0}
small = ['contract', 'tenure', 'monthlycharges']
df_train[small]
| contract | tenure | monthlycharges | |
|---|---|---|---|
| 0 | two_year | 72 | 115.50 |
| 1 | month-to-month | 10 | 95.25 |
| 2 | month-to-month | 5 | 75.55 |
| 3 | month-to-month | 5 | 80.85 |
| 4 | two_year | 18 | 20.10 |
| … | … | … | … |
| 4220 | one_year | 52 | 80.85 |
| 4221 | month-to-month | 18 | 25.15 |
| 4222 | month-to-month | 2 | 90.00 |
| 4223 | two_year | 27 | 24.50 |
| 4224 | month-to-month | 9 | 80.85 |
4225 rows × 3 columns
df_train[small].iloc[:10].to_dict(orient='records')
[{'contract': 'two_year', 'tenure': 72, 'monthlycharges': 115.5},
{'contract': 'month-to-month', 'tenure': 10, 'monthlycharges': 95.25},
{'contract': 'month-to-month', 'tenure': 5, 'monthlycharges': 75.55},
{'contract': 'month-to-month', 'tenure': 5, 'monthlycharges': 80.85},
{'contract': 'two_year', 'tenure': 18, 'monthlycharges': 20.1},
{'contract': 'month-to-month', 'tenure': 4, 'monthlycharges': 30.5},
{'contract': 'month-to-month', 'tenure': 1, 'monthlycharges': 75.1},
{'contract': 'month-to-month', 'tenure': 1, 'monthlycharges': 70.3},
{'contract': 'two_year', 'tenure': 72, 'monthlycharges': 19.75},
{'contract': 'month-to-month', 'tenure': 6, 'monthlycharges': 109.9}]
dicts_train_small = df_train[small].to_dict(orient='records')
dicts_val_small = df_val[small].to_dict(orient='records')
dv_small = DictVectorizer(sparse=False)
dv_small.fit(dicts_train_small)
DictVectorizer(sparse=False)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DictVectorizer(sparse=False)
dv_small.get_feature_names_out()
array(['contract=month-to-month', 'contract=one_year',
'contract=two_year', 'monthlycharges', 'tenure'], dtype=object)
X_train_small = dv_small.transform(dicts_train_small)
model_small = LogisticRegression()
model_small.fit(X_train_small, y_train)
LogisticRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression()
w0 = model_small.intercept_[0] #bias term
w = model_small.coef_[0] # weights
w.round(3)
array([ 0.97 , -0.025, -0.949, 0.027, -0.036])
dict(zip(dv_small.get_feature_names_out(), w.round(3)))
{'contract=month-to-month': 0.97,
'contract=one_year': -0.025,
'contract=two_year': -0.949,
'monthlycharges': 0.027,
'tenure': -0.036}
3.12 Using the model¶
We trained the logistic regression model with the full training dataset (training + validation), considering numerical and categorical features. Thus, predictions were made on the test dataset, and we evaluate the model using the accuracy metric.
In this case, the predictions of validation and test were similar, which means that the model is working well.
df_full_train
| customerid | gender | seniorcitizen | partner | dependents | tenure | phoneservice | multiplelines | internetservice | onlinesecurity | … | deviceprotection | techsupport | streamingtv | streamingmovies | contract | paperlessbilling | paymentmethod | monthlycharges | totalcharges | churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5442-pptjy | male | 0 | yes | yes | 12 | yes | no | no | no_internet_service | … | no_internet_service | no_internet_service | no_internet_service | no_internet_service | two_year | no | mailed_check | 19.70 | 258.35 | 0 |
| 1 | 6261-rcvns | female | 0 | no | no | 42 | yes | no | dsl | yes | … | yes | yes | no | yes | one_year | no | credit_card_(automatic) | 73.90 | 3160.55 | 1 |
| 2 | 2176-osjuv | male | 0 | yes | no | 71 | yes | yes | dsl | yes | … | no | yes | no | no | two_year | no | bank_transfer_(automatic) | 65.15 | 4681.75 | 0 |
| 3 | 6161-erdgd | male | 0 | yes | yes | 71 | yes | yes | dsl | yes | … | yes | yes | yes | yes | one_year | no | electronic_check | 85.45 | 6300.85 | 0 |
| 4 | 2364-ufrom | male | 0 | no | no | 30 | yes | no | dsl | yes | … | no | yes | yes | no | one_year | no | electronic_check | 70.40 | 2044.75 | 0 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 5629 | 0781-lkxbr | male | 1 | no | no | 9 | yes | yes | fiber_optic | no | … | yes | no | yes | yes | month-to-month | yes | electronic_check | 100.50 | 918.60 | 1 |
| 5630 | 3507-gasnp | male | 0 | no | yes | 60 | yes | no | no | no_internet_service | … | no_internet_service | no_internet_service | no_internet_service | no_internet_service | two_year | no | mailed_check | 19.95 | 1189.90 | 0 |
| 5631 | 8868-wozgu | male | 0 | no | no | 28 | yes | yes | fiber_optic | no | … | yes | no | yes | yes | month-to-month | yes | electronic_check | 105.70 | 2979.50 | 1 |
| 5632 | 1251-krreg | male | 0 | no | no | 2 | yes | yes | dsl | no | … | no | no | no | no | month-to-month | yes | mailed_check | 54.40 | 114.10 | 1 |
| 5633 | 5840-nvdcg | female | 0 | yes | yes | 16 | yes | no | dsl | yes | … | no | yes | no | yes | two_year | no | bank_transfer_(automatic) | 68.25 | 1114.85 | 0 |
5634 rows × 21 columns
1. First we need to create a dictionary containing the categorical and numerical data into a variable ‘dicts_full_train’.¶
dicts_full_train = df_full_train[categorical + numerical].to_dict(orient='records')
dicts_full_train[:3]
[{'gender': 'male',
'seniorcitizen': 0,
'partner': 'yes',
'dependents': 'yes',
'phoneservice': 'yes',
'multiplelines': 'no',
'internetservice': 'no',
'onlinesecurity': 'no_internet_service',
'onlinebackup': 'no_internet_service',
'deviceprotection': 'no_internet_service',
'techsupport': 'no_internet_service',
'streamingtv': 'no_internet_service',
'streamingmovies': 'no_internet_service',
'contract': 'two_year',
'paperlessbilling': 'no',
'paymentmethod': 'mailed_check',
'tenure': 12,
'monthlycharges': 19.7,
'totalcharges': 258.35},
{'gender': 'female',
'seniorcitizen': 0,
'partner': 'no',
'dependents': 'no',
'phoneservice': 'yes',
'multiplelines': 'no',
'internetservice': 'dsl',
'onlinesecurity': 'yes',
'onlinebackup': 'yes',
'deviceprotection': 'yes',
'techsupport': 'yes',
'streamingtv': 'no',
'streamingmovies': 'yes',
'contract': 'one_year',
'paperlessbilling': 'no',
'paymentmethod': 'credit_card_(automatic)',
'tenure': 42,
'monthlycharges': 73.9,
'totalcharges': 3160.55},
{'gender': 'male',
'seniorcitizen': 0,
'partner': 'yes',
'dependents': 'no',
'phoneservice': 'yes',
'multiplelines': 'yes',
'internetservice': 'dsl',
'onlinesecurity': 'yes',
'onlinebackup': 'yes',
'deviceprotection': 'no',
'techsupport': 'yes',
'streamingtv': 'no',
'streamingmovies': 'no',
'contract': 'two_year',
'paperlessbilling': 'no',
'paymentmethod': 'bank_transfer_(automatic)',
'tenure': 71,
'monthlycharges': 65.15,
'totalcharges': 4681.75}]
dv = DictVectorizer(sparse=False)
X_full_train = dv.fit_transform(dicts_full_train)
X_full_train
array([[0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 0.00000e+00,
1.20000e+01, 2.58350e+02],
[0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,
4.20000e+01, 3.16055e+03],
[0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 1.00000e+00,
7.10000e+01, 4.68175e+03],
...,
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
2.80000e+01, 2.97950e+03],
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
2.00000e+00, 1.14100e+02],
[0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 1.00000e+00,
1.60000e+01, 1.11485e+03]])
y_full_train = df_full_train.churn.values
model = LogisticRegression()
model.fit(X_full_train, y_full_train)
LogisticRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression()
6. Next we will do the same thing for our test data set.¶
dicts_test = df_test[categorical + numerical].to_dict(orient='records')
X_test = dv.fit_transform(dicts_test)
X_test
array([[0.00000e+00, 1.00000e+00, 0.00000e+00, ..., 1.00000e+00,
4.10000e+01, 3.32075e+03],
[0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 0.00000e+00,
6.60000e+01, 6.47185e+03],
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
1.20000e+01, 5.24350e+02],
...,
[0.00000e+00, 0.00000e+00, 1.00000e+00, ..., 1.00000e+00,
7.10000e+01, 3.88865e+03],
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
6.50000e+01, 5.68845e+03],
[1.00000e+00, 0.00000e+00, 0.00000e+00, ..., 0.00000e+00,
1.70000e+01, 1.74350e+03]])
y_pred = model.predict_proba(X_test)[:, 1]
len(y_pred)
1409
churn_decision = (y_pred >= 0.5)
(churn_decision == y_test).mean()
0.815471965933286
customer = dicts_test[10] # Let's use the record at index 10, we will call him customer.
x_small = dv.transform([customer])
x_small.shape
(1, 45)
model.predict_proba(X_small)[0, 1] # We predict he will probably not churn.
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Input In [139], in <cell line: 1>() ----> 1 model.predict_proba(X_small)[0, 1] NameError: name 'X_small' is not defined
y_test[10] # Actual churn, in this case our model was correct
y_test # The last one predicts that it will churn
customer = dicts_test[-1]
customer
x_small = dv.transform([customer])
model.predict_proba(x_small)[0, 1]
y_test[-1]
3.13 Summary¶
- Feature importance – risk, mutual information, correlation
- One-hot encoding can be implemented with
DictVectorizer - Logistic regression – linear model like linear regression
- Output of log reg – probability
- Interpretation of weights is similar to linear regression
In this session, we worked on a project to predict churning in customers from a company. We learned the feature importance of numerical and categorical variables, including risk ratio, mutual information, and correlation coefficient. Also, we understood one-hot encoding and implemented logistic regression with Scikit-Learn.
3.14 Explore more¶
More things
- Try to exclude least useful features
Use scikit-learn in project of last week
- Re-implement train/val/test split using scikit-learn in the project from the last week
- Also, instead of our own linear regression, use LinearRegression (not regularized) and RidgeRegression (regularized). Find the best regularization parameter for Ridge
Other projects
- Lead scoring – https://www.kaggle.com/ashydv/leads-dataset
- Default prediction – https://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients
Leave a Reply